
OpenAI又放大招,文字直接生成视频!网友:我要失业了

2月16日凌晨
OpenAI再次扔出一枚“深水炸弹”
发布了首个文生视频模型Sora
Sora可以直接输出长达60秒的视频
并且包含高度细致的背景
复杂的多角度镜头
以及富有情感的多个角色
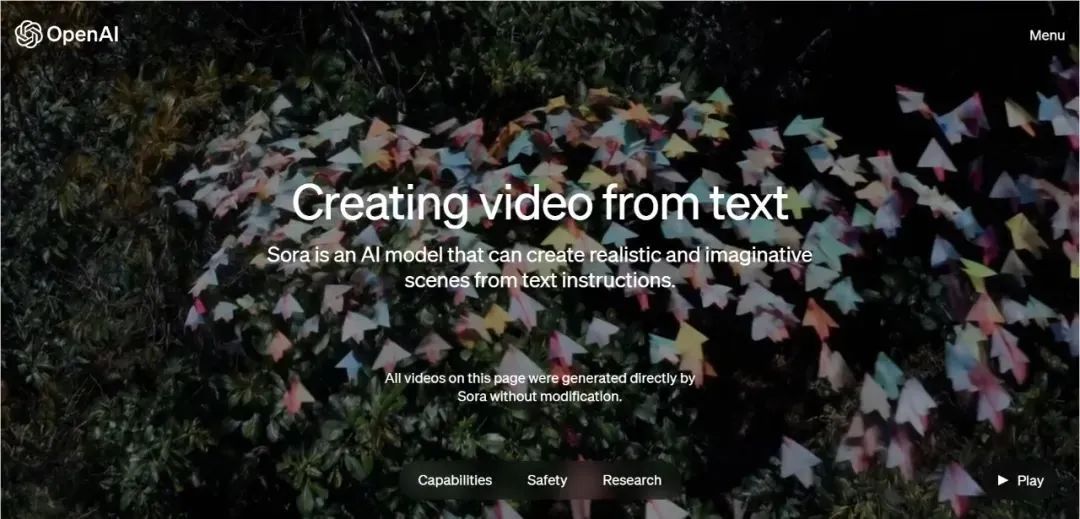
目前官网上已经更新了48个视频展示,在这些视频中,Sora不仅能准确呈现细节,还能理解物体在物理世界中的存在,并生成具有丰富情感的角色。该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
让我们看看Sora的效果
👇👇👇
例如一个Prompt(大语言模型中的提示词)的描述是:在东京街头,一位时髦的女士穿梭在充满温暖霓虹灯光和动感城市标志的街道上。

在Sora生成的视频里,女士身着黑色皮衣、红色裙子在霓虹街头行走,不仅主体连贯稳定,还有多镜头,包括从大街景慢慢切入到对女士的脸部表情的特写,以及潮湿的街道地面反射霓虹灯的光影效果。
AI想象中的龙年春节,红旗招展人山人海。有紧跟舞龙队伍抬头好奇观望的儿童,还有不少人掏出手机边跟边拍,海量人物角色各有各的行为。

行驶中的列车窗外偶遇遮挡,车内人物倒影短暂出现非常惊艳。

竖屏超近景视角下,一只蜥蜴细节拉满。

在一杯咖啡中,两艘海盗船展开了激烈的战斗,近景视频非常写实。

OpenAI表示,他们正在教AI理解和模拟运动中的物理世界,目标是训练模型来帮助人们解决需要现实世界交互的问题。
随后OpenAI解释了Sora的工作原理,Sora是一个扩散模型,它从类似于静态噪声的视频开始,通过多个步骤逐渐去除噪声,视频也从最初的随机像素转化为清晰的图像场景。Sora使用了Transformer架构,有极强的扩展性。
视频和图像是被称为“补丁”的较小数据单位集合,每个“补丁”都类似于GPT中的一个标记(Token),通过统一的数据表达方式,可以在更广泛的视觉数据上训练和扩散变化,包括不同的时间、分辨率和纵横比。
Sora是基于过去对DALL·E和GPT的研究基础构建,利用DALL·E 3的重述提示词技术,为视觉模型训练数据生成高描述性的标注,因此模型能更好地遵循文本指令。
一位YouTube博主发表了对Sora的感想,他表示内容创作行业已经永远地改变了,并且毫不夸张。“我进入YouTube世界已经15年时间,但OpenAI刚刚的展示让我无言……动画师/3D艺术家们有麻烦了,素材网站将变得无关紧要,任何人都可以无壁垒获得难以置信的产品,内容背后的‘想法’和故事将变得更加重要。”
但Sora模型当前也存在弱点
👇👇👇
OpenAI称它可能难以准确模拟复杂场景的物理原理,并且可能无法理解因果关系。例如,一个人咬了一口饼干后,饼干可能会没有咬痕,玻璃破碎的物理过程可能也无法被准确呈现。
例如“五只灰狼幼崽在一条偏僻的碎石路上互相嬉戏、追逐”的视频,狼的数量会变化,一些狼凭空出现或消失。

网友评论:
这效果也太真了吧
👇👇👇





也有网友直呼:
工作要丢了
👇👇👇
对此,你怎么看?
【来源】综合界面新闻、每日经济新闻